

Between the memories/Through time and space
A celebration of 25 years of career of Elena Christodoulidou, a trip through time and space, a collage of costumes, actions and emotions.

Too much too long
No heads, blind performers, tactical action, physical interaction.
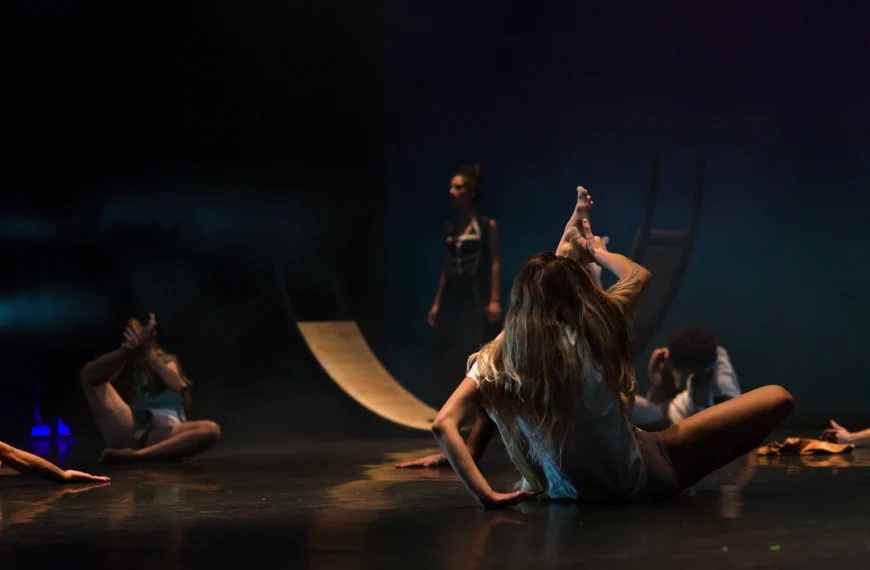
En Kryptò
The intimacy of the loneliness, the slow research of the other, the value of the connection. The secret need of the humans to find other humans.

Aerial dance with Fay Malama
Studio fun with aerial dance.

The encounter
Being connected can generate disturb, fear, discomfort. Suddenly, connections between humans become a chance.

Saline feelings
A vast space, a saline surface, an immense freedom: two friends exploring their creativity.

Looking for a North Passage
I went along the Buffer Zone to discover the landscape, but I realized quite early that I was unconsciously looking for a North Passage.

The lost continent
Cyprus is the centre of the Mediterranean, a lost continent submerged by a new geopolitics, just as water had covered Atlantis.

Humanist Cyprus
There are two anthropological sides in our civilization.
One side is based on the idea that happiness is a sum of usefulness. The other side looks for goodness in things.